AI is everywhere you look nowadays. Companies use it to provide more tailored support for their products, governments use it to analyze data on their demographic, and all of my friends use it to create and send me funny memes.
But even if you are not using it, you have heard about it. You have heard of ChatGPT. Or even Google’s Gemini. These are the chatbots that have started replacing Google search, the long-standing leader in online search engines. People have started realizing that it is much easier to search online using the same natural speech we use when talking to each other, instead of some cryptic sequence of carefully picked and meticulously typed terms.
how do chatbots work?
The way that these chatbots work is fairly complicated and a lot of work has gone into maturing the technology from an academic curiosity to the widespread adoption we see today. But it was the advancement of three main components that have brought us here. Algorithms, computational speed, and RAM.
- Research and experimentation throughout the years has led to the advancement of algorithms in the field of math, and especially algebra, which provide results more suited to our expectations of a reasoning entity.
- The shrinking in manufacturing of semiconducting material and advancements is parallel computation has lead to faster computational speeds, and thus faster and sometimes almost immediate responses to our queries when interacting with those systems.
- And RAM has become faster and more plentiful, allowing for the entirety of those systems to exist in readily available state, just like we can access all our memories at all times.
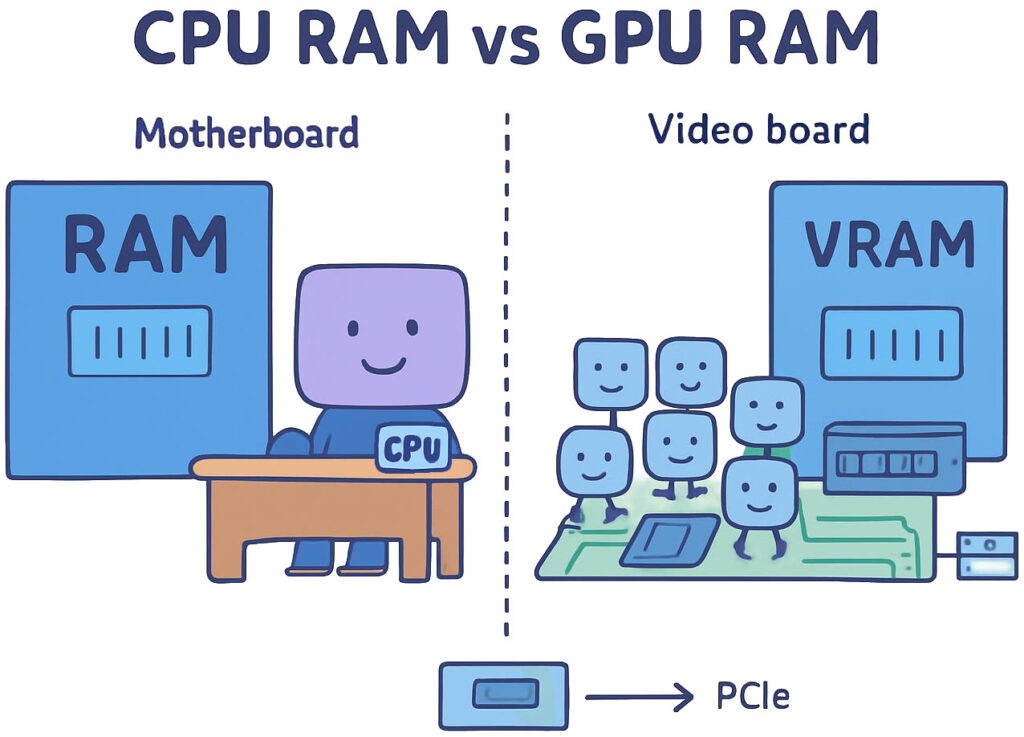
types of RAM
RAM comes in many shapes and sizes, but the two types most important for AI are CPU RAM and GPU RAM. They are both good for storing data and accessing it fast. Faster than a hard drive. But they differ in two important ways.
CPU RAM is physically located on the motherboard, right next to the processor. The processor can access the data in the CPU RAM almost immediately. We call that low latency. On the other hand, GPU RAM lives on the graphics board. When the processor needs to access the data stored there, it has to traverse the PCIe bus, a dedicated highway of sorts for all peripherals, which is a time-consuming operation. This means that GPU RAM can afford a slightly lower speed while still satisfying the PCIe bus limits, and therefore tends to have higher latency.
But GPU RAM has something that CPU RAM lacks. Higher bandwidth. Bandwidth is the amount of data you can transfer in one fell swoop. It is the size of the spoon. GPU RAM can move around huge chunks of memory with minimal effort. CPU RAM not so much. But for AI, and the way the algorithms are designed, this specific feature of GPU RAM is essential.
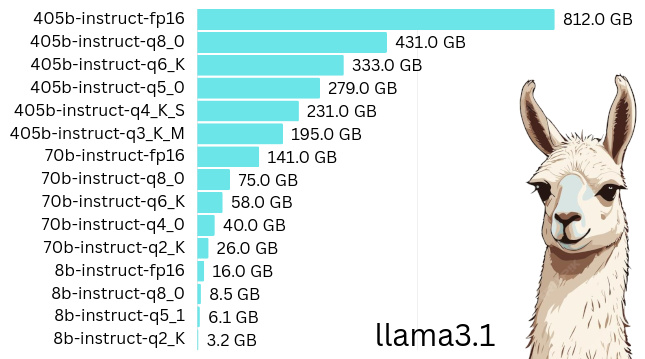
how much RAM?
We do not know exactly how many gigabytes of RAM the current state of the art chatbots need to run, as this information isn’t publicly disclosed by the big players.
We do have however, many open source models such as llama released by Meta, Deepseek, GLM, Kimi, and more. These perform closely to their closed source equivalents, so we can safely deduce that their memory requirements would be in the same ballpark. If we try to download any of those open source models, we will soon discover they are very big, ranging from a few hundred gigabytes to over 1 terabyte!
There is no graphics board with so much RAM, although Nvidia’s H200 with a whopping 141 gigabytes does not fail to impress. This is why companies deploying this technology use multiple graphics boards, which create a pool of memory capable of loading such humongous models in their entirety.

I want to play, too
All these online chatbots are great, but what if we wanted to have our very own? Many enthusiasts do exactly that nowadays, with privacy as their chief reason among many.
There are many open source programs (read free) that employ the popular “transformer” algorithm needed to create a chatbot. And most of the newer CPUs provide computational speeds that are more than enough for running those programs. But RAM might be an issue.
Most consumer grade video boards come with single digit gigabytes of memory, a far cry from the hundreds of gigabytes of RAM needed to run the current state of the art models. And buying multiple video boards is prohibitive to the average budget.
Fortunately, there are many smaller models, too. These models do not perform on par with the state of the art models, but they can be good enough depending on how they are used. A chatbot made to write poems does not need to be good at math, and a chess teacher can do without cooking expertise.
Although these smaller models have sizes that fit in single video boards, performance still depends on the size of the model, having bigger models exhibit more human-like characteristics and logic. This is why, we must try to maximize the available RAM in a system and that means getting the video board with the most RAM we can get our hands on. Nowadays, there are many models within the 12 to 24 gigabytes range which are considered to make excellent chatbots.
and that CPU RAM we talked about?
Running a model that is bigger in size than the amount of available RAM in our video board used to be impossible. Luckily, advancements in the model representation structure brought us GGUF, a new file type. GGUF models can be loaded on either GPU RAM or CPU RAM, or even be split between the two in whatever portions are necessary. This allows us to run bigger models that can fit within the total memory of our entire system.
This convenience though comes at a cost. With CPU RAM having smaller bandwidth, models that are loaded in part, or in their entirety, in CPU RAM run slower, leading to chatbots that have slower thinking and response speeds in turn. This is why keeping the entire model in GPU RAM is always preferred.
a memorable conclusion
The pace of innovation in language models and machine learning in general has been brisk. We have seen models become smaller and smaller in size, while their capabilities are retained. It would not be a stretch of imagination to envision chatbots similar to the current state of the art ones running in our local systems in the near future.
At the same time, there will always be a spectrum of models to choose from. And if the size of the model continues to largely signify the quality of the chatbot, we will always be better off having the most available fast RAM in our disposal.